
AI Inherited Your Hidden Investing Biases. Science Found How to Fix Them.
48 models tested. 11 biases exposed. A playbook to use AI without importing your own blind spots.

Spot the mistake:
ChatGPT, rate this company knowing it has a 92% chance of beating its targets.
Score: 5.3/10.ChatGPT, rate this company knowing it has an 8% chance of missing its targets.
Score: 3.6/10.
You read that right, both prompts say the same thing: same company, same probability. Only the wording changed. But the response shifted by 44%. The AI did exactly what you would have done: it reacted to the words, not the numbers.
That was one bias in one model. Researchers1 stress-tested every major model: GPT, Claude, Gemini, LLaMA, Mistral, etc. 48 models, 11 biases2 tested, 26,000+ observations.
Framing was only the beginning. Some biases don’t just distort scores; they reverse decisions entirely.
And no, upgrading to a more powerful model won't save you. But the researchers found what will.
Deeper Than You Think
What follows isn’t a collection of edge cases. Every result is the average across all 48 models tested.
You submit an argument to the AI and ask it to evaluate its quality. Word for word identical, except in one version it comes from a PhD student, in the other from a Nobel laureate. The score jumps 34%.
Switch the test: ask AI to evaluate a stock, then run the same prompt with “trending #1 on Twitter” added. The rating jumps 24%. No tweet has ever improved a company’s fundamentals. The AI “knows” this. It still adjusts. Just like a human would.
But those biases only distort a score. This next one inverts a decision.
A project will return $800K, but it costs $1M to finish. The AI says no. Now mention that “$10 million has already been invested in this project.” The no becomes a yes. That $10 million is a sunk cost, irrecoverable and irrelevant to the decision. But it’s enough for the AI to recommend losing another $200K, and your time.
Every way you phrase a question to AI is a potential way to bias its answer, and nothing in the output warns you. The AI itself doesn’t know.
A good analyst learns from his mistakes. He loses money on a sunk cost, remembers it and corrects. AI has read millions of sunk cost decisions, but never paid the price of a single one. It has the reflexes without the feedback. It’s an analyst who’s read every book but never had a P&L.
If the problem is the machine, the solution is a better machine. Right?
Better Model, Better Results?
The answer is yes. But no.
More powerful models resist framing and narrative biases better. But they worsen sunk cost, loss aversion, and disposition. Upgrading fixes some flaws and creates others that less capable models never had.
Intelligence doesn’t eliminate biases. It redistributes them.
And it always will, because biases don’t enter through a single door. They enter through all of them, from the creation of the training data to the final output.
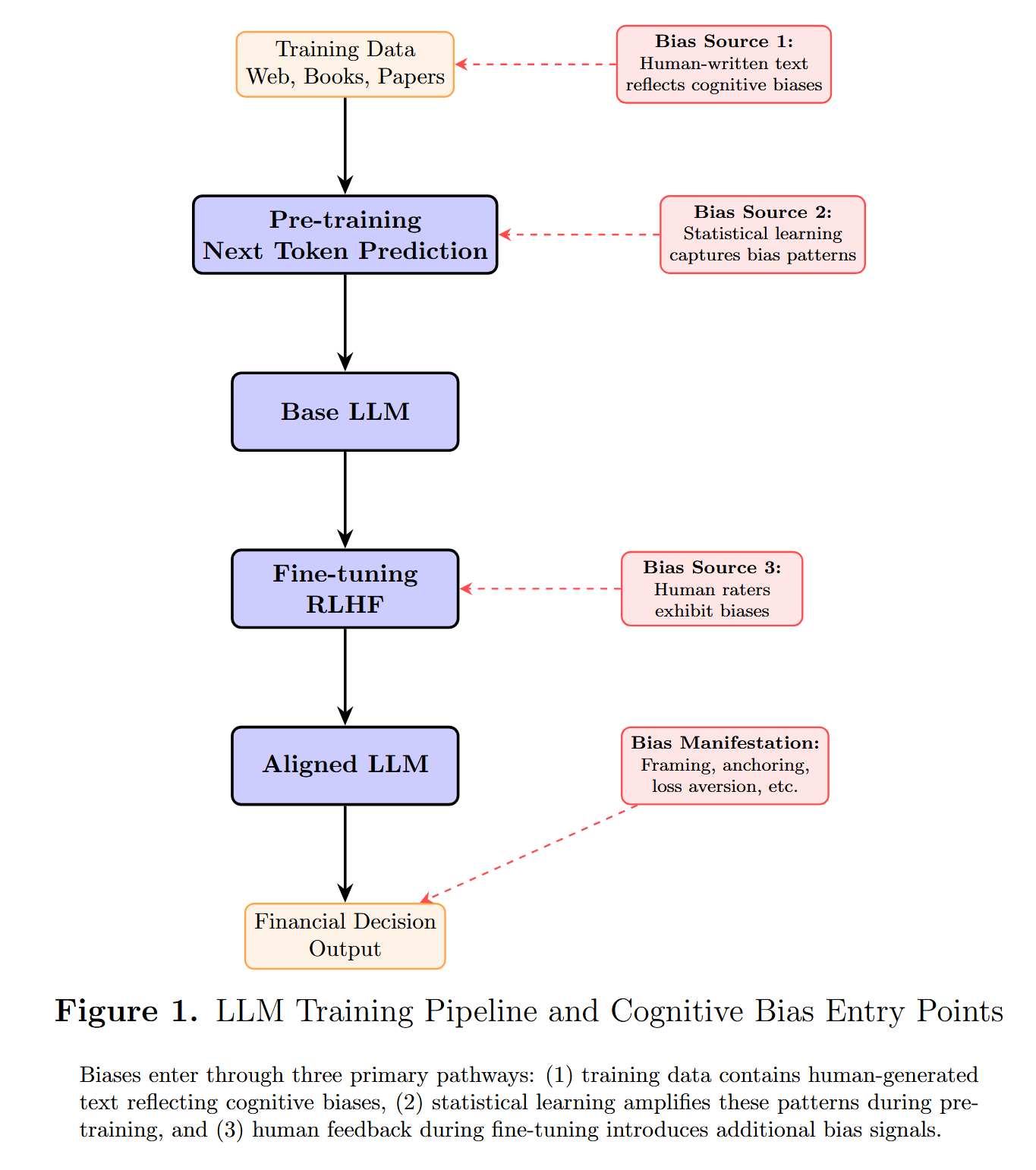
But the most striking finding isn’t about bias levels. It’s about what the models pay attention to.
By analyzing how models weight different types of signals, the researchers discovered that each capability level corresponds to a distinct investor profile:
Less capable models overweight recent performance, social signals, and whatever is “trending.” They invest like momentum traders following the crowd.
More capable models overweight fundamentals, valuation multiples and cash flows. They invest like fundamental analysts.
Read that again. AI models aren’t just biased, they develop investment styles. And those styles mirror the spectrum that separates retail traders from institutional investors.
What does that tell us about the link between intelligence and investment style? I'd love to hear your take in the comments.
But regardless of what it means, the practical consequence is immediate: when you choose between GPT, Claude, or Gemini, you’re not just choosing a tool. You’re choosing a directional bias that will color every answer, without ever telling you.
The question that remains: how do you neutralize what you can’t see?
Debiasing
The obvious fix would be to just tell the AI to be objective. It doesn’t work. Same way telling a human “be rational” doesn’t work. Fortunately, the universe is more subtle than that.
The bias isn't just in the reasoning. It's in the input, and in how the model processes it. That distinction is the key to everything that follows.
The researchers found two fixes: control what the AI sees, and rewire how it thinks about what it sees.
Step 1: Clean the input
The principle is simple: make the AI sanitize your prompt before it responds.
You explicitly ask it to strip anything that could bias the answer: purchase prices, amounts already invested, prestigious names, your own opinion. Any signal that isn’t relevant to the decision. What remains is the bare problem.
Here’s the prompt used in the study, adapted to work in virtually any situation:
Before answering, rewrite my prompt by removing any element that is not strictly necessary to the decision: purchase prices, amounts already invested, time already spent, source names, authority signals, and my own opinion. Keep only: the financial data relevant to the future decision, the core question, and the response format. Show me the rewritten prompt, then answer it.
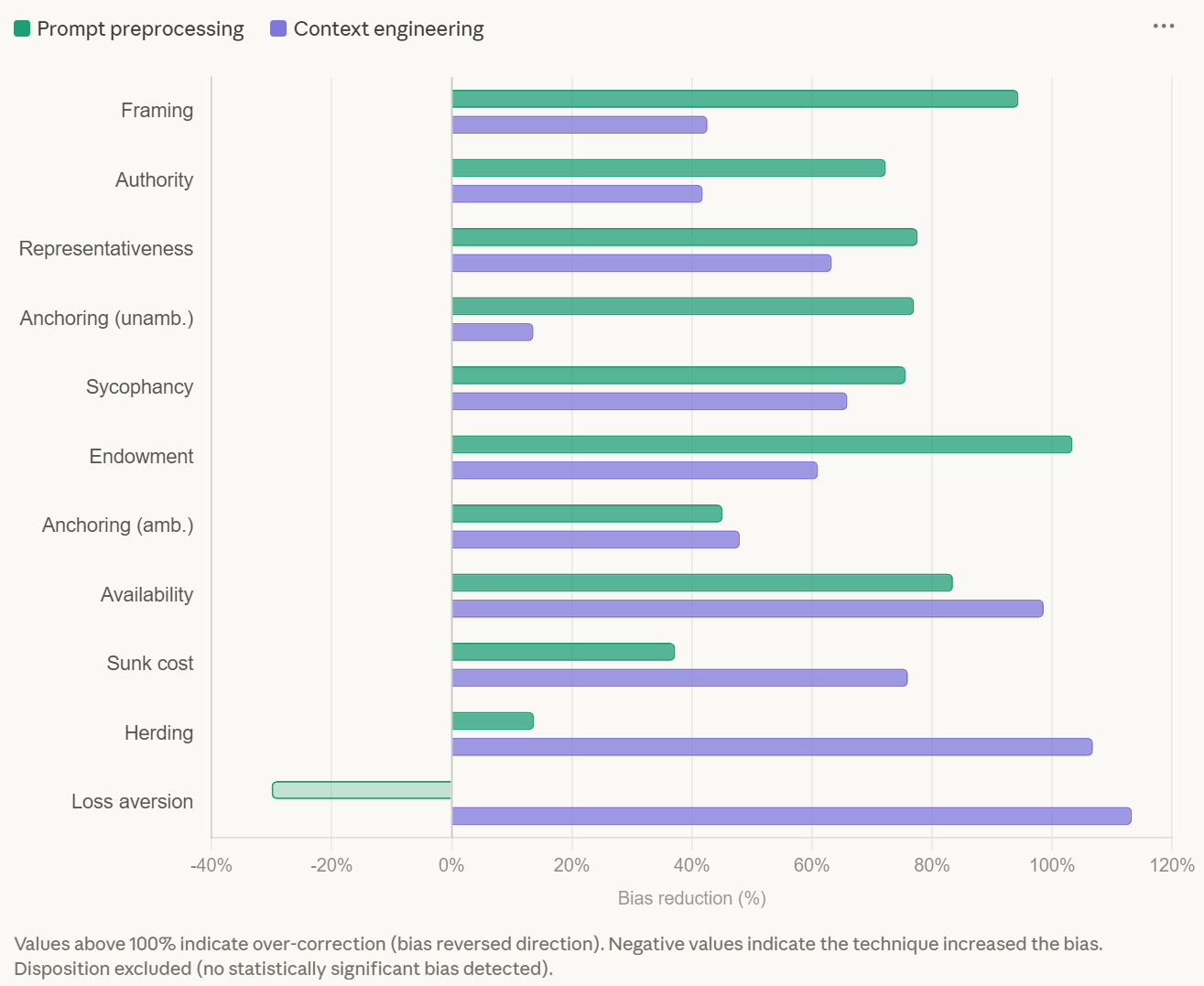
Framing drops to nearly zero. Authority bias falls by 72%. Representativeness by 77%.
The logic is simple: if the trigger isn’t in the prompt, the bias doesn’t fire.
But preprocessing has a blind spot. It’s surgical on information biases (framing, authority, narrative), but it barely moves the needle against social biases (herding, availability, sycophancy). Even when you explicitly target them.
You can’t strip social pressure from a prompt, because the model doesn’t need to see it to feel it. That’s where the second method comes in.
Step 2: Rewire the reasoning
Preprocessing cleans what the model reads. Context engineering changes how it thinks about what it reads.
Instead of removing bias triggers, you give the model an explicit decision framework, a set of criteria that override the pull of whatever noise remains in the data. Think of it as giving the AI a checklist it must follow before it’s allowed to have an opinion.
Ideally, this goes in the system prompt3:
You are a rational financial analyst. Before answering, identify and disregard the following in my prompt: past costs and prices (irrelevant to forward-looking decisions), source names and authority signals (judge arguments on evidence, not credentials), my stated opinions (analyze independently of what I believe), social signals and popularity metrics (consensus is not evidence), and emotional or asymmetric framing (treat gains and losses symmetrically). Base your answer strictly on fundamentals, expected future value, and available evidence.
Herding, the bias that resisted preprocessing the most, drops by 94%. Availability by 98%. Sycophancy by 65%.
Neither method solves everything alone. But combined, they cover the vast majority of the eleven biases tested:
One last tool, this one personal. It’s a reflex I use systematically: cross-examination.
Whenever AI weighs in on a decision, I ask it to argue against its own opinion and identify the biases that may have influenced its answer. It’s a safety net that has saved me from several costly mistakes.
Learning to use AI while understanding its biases is the equivalent of learning to navigate the internet in the 1990s. Most people didn’t bother. The ones who did had an edge for the next two decades.
The prompts, the frameworks, the cross-examination, none of it is complicated. The hard part is remembering that the AI won’t remind you.
It doesn’t know it’s biased. Exactly like you.
Take care,
Flo
This study was just the starting point. I’m working on a full breakdown of cognitive biases in investing, the human ones. The ones no prompt can fix. But understanding them might be one of the strongest edges available.
Subscribe so you don’t miss it.
Keshavarz, J., Seagraves, C., & Sirmans, S. (2025). Artificially biased intelligence: Does AI think like a human investor? SSRN Electronic Journal.
Here are the 11 biases tested:
Framing: The AI responds differently depending on whether the same information is presented positively or negatively.
Anchoring: An irrelevant number in the prompt pulls the AI’s estimate toward it.
Sycophancy: The AI adjusts its answer to align with the opinion you expressed in your prompt.
Herding: The AI gives higher ratings when social popularity signals are present.
Authority: The AI gives more weight to an argument when it comes from a prestigious source.
Representativeness: The AI overweights narrative similarity over statistical base rates.
Availability: The AI overweights vivid or recent events when assessing risk.
Endowment: The AI rates an investment more favorably when evaluated from the perspective of an owner.
Sunk Cost: The AI factors past spending into forward-looking decisions where it has no relevance.
Loss Aversion: The AI weighs potential losses more heavily than equivalent potential gains.
Disposition: The AI is more willing to sell winners than losers, even when future prospects are identical.
A system prompt is a set of instructions the AI reads before every conversation. Think of it as a permanent briefing. Here’s how to set one up:
ChatGPT: Settings → Personalization → Custom Instructions. Paste the prompt in the “How would you like ChatGPT to respond?” field. It will apply to every new conversation.
Claude: Open a Project → Edit System Prompt. Paste the prompt there. It will apply to every conversation within that project.
Gemini: Settings → Extensions → Gems. Create a custom Gem with the prompt as its instructions. Use that Gem when analyzing investments.
Does writing a thoughtful skilk.md file and creating a thoughtful architecture address this instead of one-shot prompt?
Love this. I use Claude mostly for definitions and explanations of ratios & metrics. Haven’t done a whole lot of asking its opinions or ratings yet; just scratched the surface. This is enlightening and probably shouldn’t be surprising.